
The Failure That Triggered the Work
An analyst asked our internal AI platform to analyze last month’s customer cases for temperature issues. The response was thorough. It cited specific case numbers, SKUs, error codes, and volume statistics. It looked like exactly what she had asked for.
It was mostly fabricated.
Six case IDs appeared in the retrieved context. The remaining case numbers in the response did not exist. The model had generated plausible-looking alphanumeric IDs that matched the formatting conventions of real ticket numbers, populated them with invented details, and presented the whole thing as a factual summary. The response had a 200 OK status, sub-second latency, and zero errors at the infrastructure layer. Nothing in our monitoring stack would have caught it.
The analyst caught it because she knew the actual case numbers. Most users would not have. And this is the failure mode that makes LLM hallucination genuinely dangerous in an enterprise context. As Datadog noted in their May 2025 write-up on LLM observability: “RAG does not prevent hallucinations. LLMs can still fabricate responses while citing sources, giving users a false sense of confidence.” The agent had retrieved real context. It then went beyond that context without any indication that it was doing so.
We needed a way to catch this at the moment the response occurs, not days later when someone files a complaint.
The Design Question
The obvious first move is to call a second LLM to score faithfulness. Every major framework does this. RAGAS, DeepEval, and Datadog’s LLM Observability product all use a judge model that breaks the response into factual claims and then verifies each claim against the retrieved context. It is a reasonable approach for prose-level faithfulness.
We did not take that route, for three reasons.
First, cost. Every agent response already incurred retrieval and generation costs. Adding a judge call on top of every response adds latency and per-token spend that compounds at volume.
Second, determinism. LLM-as-a-judge scoring is non-deterministic by design. Running the same response twice can produce different scores. That is a poor foundation for an audit log that compliance teams are expected to trust. Research published at EMNLP 2025 found that even the best LLM judges achieve balanced accuracy below 78% on hallucination detection benchmarks.
Third, debuggability. A score of 0.72 from a judge model tells you something went wrong. It does not tell you whether the agent fabricated a case number, invented a statistic, or cited a SKU that does not exist.
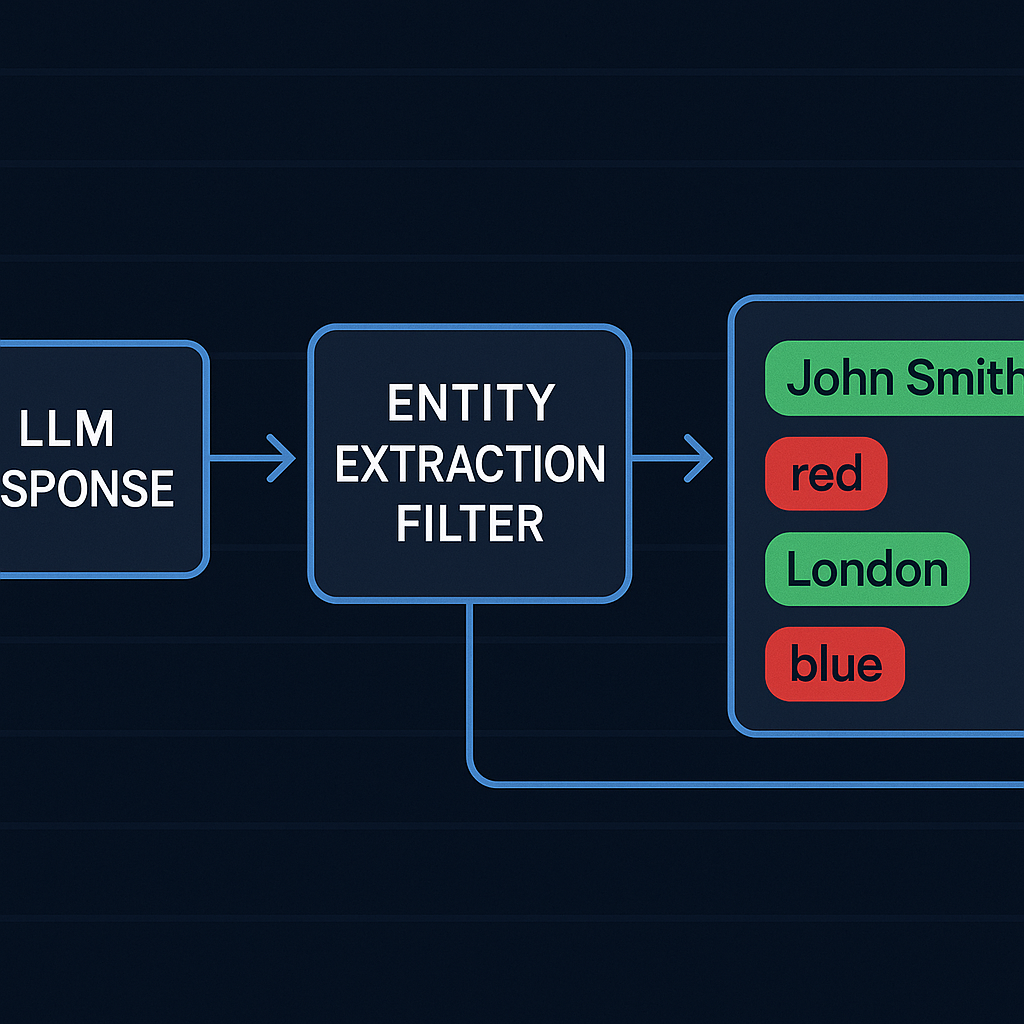
Entity extraction gives us narrower scope but better properties on every other dimension. It is deterministic, costs zero additional LLM calls, and produces a per-kind breakdown that points directly at the problem.
What I Built
Entity Extraction and Matching
Every assistant response runs through an extraction pass that identifies seven categories of structured entities:
- Case numbers (alphanumeric IDs matching customer support ticket formats)
- SKUs and model numbers
- Error codes
- Percentages
- Dollar amounts
- Integer counts with clear contextual meaning, such as “1,234 incidents”
- Date scopes, such as “Q3 2024” or “April 2026”
Each extracted entity is normalized before comparison. Normalization is case-insensitive, strips commas from numeric strings, and collapses whitespace. The same normalization runs over the retrieved context chunks the agent actually saw during retrieval. We then compute the canonical faithfulness ratio: supported entities divided by total entities. A response that cites ten entities, eight of which appear in the retrieved context, scores 0.8.
Our default threshold is 0.9. The industry commonly benchmarks at 0.8 or above, but we set a more conservative threshold from the start. As the Qaskills RAGAS guide puts it, teams should “always set thresholds by baselining your own system rather than copying numbers.” We will adjust based on production data.
The Audit Log Row
When a response falls below threshold, the system writes a structured row to the audit log. The action field is always quality.faithfulness_violation. The row carries:
score: the overall ratio as a floatthreshold: the configured threshold at time of evaluationper_kind_breakdown: a map from entity category to its own supported/total ratiounsupported_sample: a small array of the specific entities that failed the matchresponse_excerpt: the first N characters of the assistant responsecontext_excerpt: a truncated concatenation of the retrieved chunks
That structure matters. A SQL group-by on action across a date range answers “how often is the agent failing faithfulness checks.” A group-by on the per-kind fields answers “which entity type is driving violations.” Those are different questions with different fixes.
The module sits under 350 lines. There is no LLM in the scoring path. The whole thing runs inline on every response.
What Was Learned
Per-Kind Breakdown is the Most Actionable Output
Aggregate faithfulness scores are hard to act on. “The agent hallucinates” is a description of a symptom. “The agent fails to ground percentages in retrieved context at a measurably higher rate than it fails to ground case numbers” is something a prompt engineer can investigate and address. The per-kind breakdown is what converts a monitoring metric into a task.
This aligns with an emerging practice in the field. As FutureAGI noted in their 2025 analysis, the term “hallucination” is being split into concrete failure modes so teams stop reporting a single number and start reporting per-mode rates.
Passive Logging Before Inline Gating
The feature does not block responses. It logs violations. This was a deliberate choice, not a deferral.
Setting a threshold for an inline gate before you have production data is guesswork. If the gate is too strict, it starts blocking valid responses, and the team faces pressure to loosen it. If it is too loose, it never fires. Creating the logger first gives us the calibration data. Real production traffic tells us where the score distribution actually sits, which entity categories generate false positives, and whether 0.9 is the right threshold or needs adjustment.
Swept.ai draws a clean distinction between observability (detecting that a hallucination occurred) and supervision (preventing it from reaching the user). We are in the observability phase. Supervision comes after the threshold is earned.
The Regression Test
We pinned the original incident as a regression test. The six real case IDs, the retrieved context that contained them, and a fabricated response that adds imaginary case numbers are now a fixed test case in CI. The faithfulness checker must flag that response on every run.
This is easy to underrate. Prompt changes silently degrade LLM performance. A wording change that improves one behavior can quietly reintroduce a failure that was fixed months ago. Without a pinned test, the team fixes a hallucination once, closes the ticket, and discovers the regression when a user complains again. With it, the original failure becomes a permanent quality contract. Model swap, prompt revision, retrieval pipeline change, all of them run against the same incident. Deepchecks puts it plainly: “keep a small hard-set of regressions, and review failures the way you review production bugs.”
What’s Next
Once production data has calibrated the threshold, the same module moves inline. A response that scores below threshold gets held and the agent either retries with a more grounded prompt or surfaces a low-confidence indicator to the user.
We also plan to wire faithfulness into the development feedback loop as a fifth validator gate alongside the existing checks. Open questions remain around semantic equivalence. If the retrieved context says “47 incidents” and the response says “around 50,” the entity does not match but the claim is arguably faithful. Handling numeric proximity and paraphrase without reintroducing LLM calls is the design problem we have not solved yet.
The structured audit log is already earning its keep with compliance stakeholders who need to demonstrate due diligence on AI-generated outputs. That use case does not require inline gating at all. The log is the governance artifact they need.